Data Contract CLI



![]()
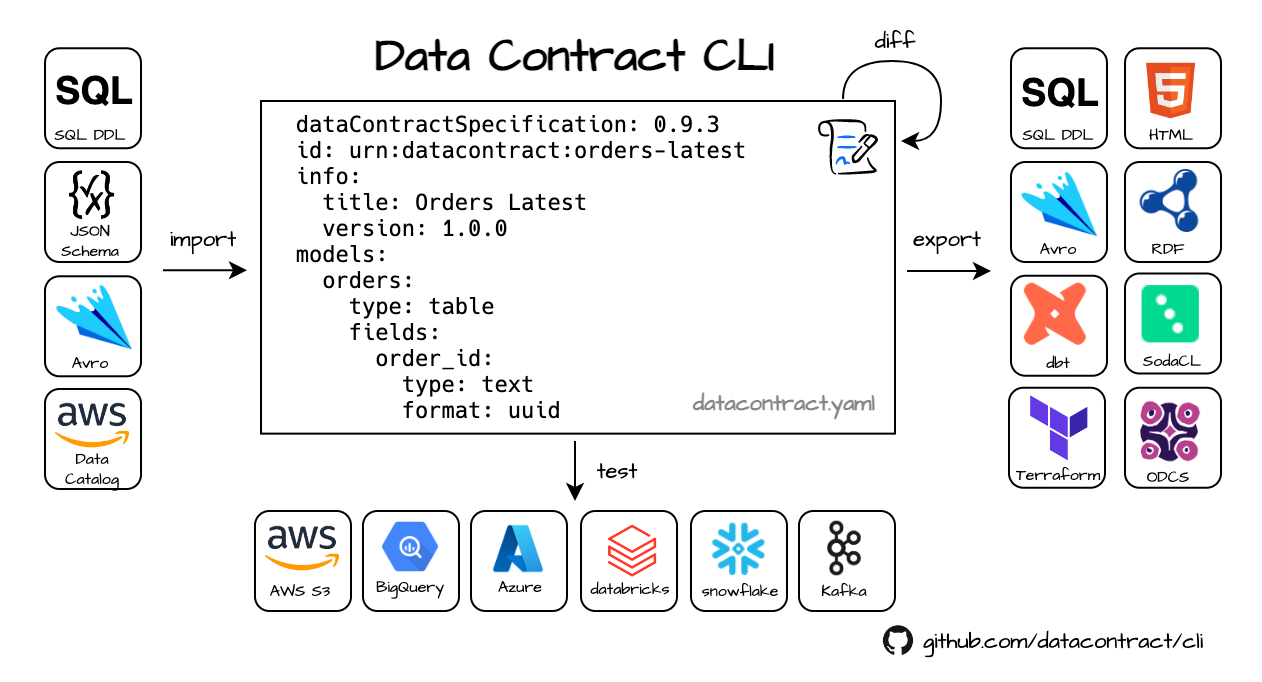
The datacontract CLI is an open-source command-line tool for working with data contracts.
It natively supports the Open Data Contract Standard to lint data contracts, connect to data sources and execute schema and quality tests, and export to different formats.
The tool is written in Python.
It can be used as a standalone CLI tool, in a CI/CD pipeline, or directly as a Python library.
📖 Full documentation: docs.datacontract.com
Quick links: Quickstart · Commands · Best Practices · Custom Export and Import · Release Notes · Development Setup
For LLMs: cli.datacontract.com/llms.txt · docs.datacontract.com/llms.txt · docs.datacontract.com/llms-full.txt
Getting started
Let’s look at this data contract: https://datacontract.com/orders-v1.odcs.yaml
We have a servers section with endpoint details to a Postgres database, schema for the structure and semantics of the data, service levels and quality attributes that describe the expected freshness and number of rows.
This data contract contains all information to connect to the database and check that the actual data meets the defined schema specification and quality expectations. We can use this information to test if the actual data product is compliant to the data contract.
Let’s use uv to install the CLI (or use the Docker image),
$ uv tool install --python python3.11 --upgrade 'datacontract-cli[all]'
Now, let’s run the tests:
$ export DATACONTRACT_POSTGRES_USERNAME=datacontract_cli.egzhawjonpfweuutedfy
$ export DATACONTRACT_POSTGRES_PASSWORD=jio10JuQfDfl9JCCPdaCCpuZ1YO
$ datacontract test https://datacontract.com/orders-v1.odcs.yaml
# returns:
Testing https://datacontract.com/orders-v1.odcs.yaml
Server: production (type=postgres, host=aws-1-eu-central-2.pooler.supabase.com, port=6543, database=postgres, schema=dp_orders_v1)
╭────────┬──────────────────────────────────────────────────────────┬─────────────────────────┬─────────╮
│ Result │ Check │ Field │ Details │
├────────┼──────────────────────────────────────────────────────────┼─────────────────────────┼─────────┤
│ passed │ Check that field 'line_item_id' is present │ line_items.line_item_id │ │
│ passed │ Check that field line_item_id has type UUID │ line_items.line_item_id │ │
│ passed │ Check that field line_item_id has no missing values │ line_items.line_item_id │ │
│ passed │ Check that field 'order_id' is present │ line_items.order_id │ │
│ passed │ Check that field order_id has type UUID │ line_items.order_id │ │
│ passed │ Check that field 'price' is present │ line_items.price │ │
│ passed │ Check that field price has type INTEGER │ line_items.price │ │
│ passed │ Check that field price has no missing values │ line_items.price │ │
│ passed │ Check that field 'sku' is present │ line_items.sku │ │
│ passed │ Check that field sku has type TEXT │ line_items.sku │ │
│ passed │ Check that field sku has no missing values │ line_items.sku │ │
│ passed │ Check that field 'customer_id' is present │ orders.customer_id │ │
│ passed │ Check that field customer_id has type TEXT │ orders.customer_id │ │
│ passed │ Check that field customer_id has no missing values │ orders.customer_id │ │
│ passed │ Check that field 'order_id' is present │ orders.order_id │ │
│ passed │ Check that field order_id has type UUID │ orders.order_id │ │
│ passed │ Check that field order_id has no missing values │ orders.order_id │ │
│ passed │ Check that unique field order_id has no duplicate values │ orders.order_id │ │
│ passed │ Check that field 'order_status' is present │ orders.order_status │ │
│ passed │ Check that field order_status has type TEXT │ orders.order_status │ │
│ passed │ Check that field 'order_timestamp' is present │ orders.order_timestamp │ │
│ passed │ Check that field order_timestamp has type TIMESTAMPTZ │ orders.order_timestamp │ │
│ passed │ Check that field 'order_total' is present │ orders.order_total │ │
│ passed │ Check that field order_total has type INTEGER │ orders.order_total │ │
│ passed │ Check that field order_total has no missing values │ orders.order_total │ │
╰────────┴──────────────────────────────────────────────────────────┴─────────────────────────┴─────────╯
🟢 data contract is valid. Run 25 checks. Took 3.938887 seconds.
Voilà, the CLI tested that the YAML itself is valid, all records comply with the schema, and all quality attributes are met.
To test your own data, import a contract straight from an existing table (this also generates the servers block) and run the tests against the actual data:
$ datacontract import snowflake --source <account> --database ORDER_DB --schema PUBLIC --output datacontract.yaml
$ datacontract test datacontract.yaml
Copy-paste guides with credentials setup are available for Snowflake, BigQuery, Databricks, and 15+ other sources.
We can also use the data contract metadata to export in many formats, e.g., to generate a SQL DDL:
$ datacontract export sql https://datacontract.com/orders-v1.odcs.yaml
# returns:
-- Data Contract: orders
-- SQL Dialect: postgres
CREATE TABLE orders (
order_id UUID not null primary key,
customer_id text not null,
order_total integer not null,
order_timestamp TIMESTAMPTZ,
order_status text
);
CREATE TABLE line_items (
line_item_id UUID not null primary key,
sku text not null,
price integer not null,
order_id UUID
);
Or generate an HTML export:
$ datacontract export html --output orders-v1.odcs.html https://datacontract.com/orders-v1.odcs.yaml
Usage
# create a new data contract from example and write it to odcs.yaml
$ datacontract init odcs.yaml
# edit the data contract in the Data Contract Editor (web UI)
$ datacontract edit odcs.yaml
# lint the odcs.yaml and stop after the first validation error (default).
$ datacontract lint odcs.yaml
# show a changelog between two data contracts
$ datacontract changelog v1.odcs.yaml v2.odcs.yaml
# execute schema and quality checks (define credentials as environment variables)
$ datacontract test odcs.yaml
# generate dbt tests from a contract into your dbt project, then run them
# (omit the contract to sync/test every *.odcs.yaml in the project)
$ datacontract dbt sync orders.odcs.yaml --project-dir ./warehouse
$ datacontract dbt test orders.odcs.yaml --project-dir ./warehouse
# export data contract as html (other formats: avro, dbt-models, dbt-sources, dbt-staging-sql, jsonschema, odcs, rdf, sql, sodacl, terraform, ...)
$ datacontract export html datacontract.yaml --output odcs.html
# import sql (other formats: avro, glue, bigquery, jsonschema, excel ...)
$ datacontract import sql --source my-ddl.sql --dialect postgres --output odcs.yaml
# import from Excel template
$ datacontract import excel --source odcs.xlsx --output odcs.yaml
# export to Excel template
$ datacontract export excel --output odcs.xlsx odcs.yaml
Programmatic (Python)
from datacontract.data_contract import DataContract
data_contract = DataContract(data_contract_file="odcs.yaml")
run = data_contract.test()
if not run.has_passed():
print("Data quality validation failed.")
# Abort pipeline, alert, or take corrective actions...
How to
- How to integrate Data Contract CLI in your CI/CD pipeline as a GitHub Action
- How to run the Data Contract CLI API to test data contracts with POST requests
- How to run Data Contract CLI in a Databricks pipeline
Installation
Choose the most appropriate installation method for your needs:
uv
The preferred way to install is uv:
uv tool install --python python3.11 --upgrade 'datacontract-cli[all]'
uvx
If you have uv installed, you can run datacontract-cli directly without installing:
uv run --with 'datacontract-cli[all]' datacontract --version
pip
Python 3.10, 3.11, and 3.12 are supported. We recommend using Python 3.11.
python3 -m pip install 'datacontract-cli[all]'
datacontract --version
pip with venv
Typically it is better to install the application in a virtual environment for your projects:
cd my-project
python3.11 -m venv venv
source venv/bin/activate
pip install 'datacontract-cli[all]'
datacontract --version
pipx
pipx installs into an isolated environment.
pipx install 'datacontract-cli[all]'
datacontract --version
Docker
You can also use our Docker image to run the CLI tool. It is also convenient for CI/CD pipelines.
docker pull datacontract/cli
docker run --rm -v ${PWD}:/home/datacontract datacontract/cli
You can create an alias for the Docker command to make it easier to use:
alias datacontract='docker run --rm -v "${PWD}:/home/datacontract" datacontract/cli:latest'
Note: The output of Docker command line messages is limited to 80 columns and may include line breaks. Don’t pipe docker output to files if you want to export code. Use the --output option instead.
Optional Dependencies (Extras)
The CLI tool defines several optional dependencies (also known as extras) that can be installed for using with specific servers types. With all, all server dependencies are included.
uv tool install --python python3.11 --upgrade 'datacontract-cli[all]'
A list of available extras:
| Dependency | Installation Command |
|---|---|
| Amazon Athena | pip install datacontract-cli[athena] |
| Avro Support | pip install datacontract-cli[avro] |
| Azure Integration | pip install datacontract-cli[azure] |
| Google BigQuery | pip install datacontract-cli[bigquery] |
| CSV | pip install datacontract-cli[csv] |
| Databricks Integration | pip install datacontract-cli[databricks] |
| Databricks Runtime | pip install datacontract-cli[databricks-runtime] (inside Databricks, where the cluster provides PySpark) |
| DataFrame (Spark) | pip install datacontract-cli[dataframe] |
| DBML | pip install datacontract-cli[dbml] |
| DuckDB (local/S3/GCS/Azure file testing) | pip install datacontract-cli[duckdb] |
| Excel | pip install datacontract-cli[excel] |
| GCS Integration | pip install datacontract-cli[gcs] |
| Iceberg | pip install datacontract-cli[iceberg] |
| Impala | pip install datacontract-cli[impala] |
| Kafka Integration | pip install datacontract-cli[kafka] |
| MySQL Integration | pip install datacontract-cli[mysql] |
| Oracle | pip install datacontract-cli[oracle] |
| Parquet | pip install datacontract-cli[parquet] |
| PostgreSQL Integration | pip install datacontract-cli[postgres] |
| protobuf | pip install datacontract-cli[protobuf] |
| RDF | pip install datacontract-cli[rdf] |
| Amazon Redshift | pip install datacontract-cli[redshift] |
| S3 Integration | pip install datacontract-cli[s3] |
| Snowflake Integration | pip install datacontract-cli[snowflake] |
| Microsoft SQL Server | pip install datacontract-cli[sqlserver] |
| Trino | pip install datacontract-cli[trino] |
| API (run as web server) | pip install datacontract-cli[api] |
Documentation
📖 The full documentation is at docs.datacontract.com.
It covers everything in depth, including the complete command reference:
- Quickstart — install and run your first test
- Open Data Contract Standard — the contract format
- Test your Data — schema & quality tests against 18+ data sources
- Define your Quality Rules — SQL, library, text, and custom checks
- Sync with dbt · Edit your contract
- Imports and Exports — convert to/from 25+ formats
- API and Python Library
- Command reference —
init,lint,test,export,import,dbt,ci,catalog,publish,api, and more
Development Setup
- Install uv
- Python base interpreter should be 3.11.x.
- A JDK (17 or 21) must be installed for the Spark-based tests (e.g.
test_test_kafka.py,test_test_delta.py,test_test_dataframe.py,test_import_spark.py). Java 25 is not yet supported. On macOS and Linux you can install one with SDKMAN:sdk install java 21.0.11-tem(or any 21.x build fromsdk list java). Verify withjava --version. - Docker engine must be running to execute the tests.
sdk use java 21.0.11-tem
uv python pin 3.11
uv venv
uv pip install -e '.[dev]'
uv run ruff check
uv run pytest
Contribution
We are happy to receive your contributions. Propose your change in an issue or directly create a pull request with your improvements.
Before creating a pull request, please make sure that all tests are passing (uv run pytest) and
your code is properly formatted (ruff format). Create a changelog entry and reference fixed
issues (if any).
Troubleshooting
Windows: Some tests fail
Run in WSL. (We need to fix the paths in the tests so that normal Windows will work, contributions are appreciated)
PyCharm does not pick up the .venv
This uv issue might be relevant.
Try to sync all groups:
uv sync --all-groups --all-extras
Errors in tests that use PySpark (e.g. test_test_kafka.py)
Ensure you have a JDK 17 or 21 installed. Java 25 causes issues.
java --version
Docker Build
docker build -t datacontract/cli .
docker run --rm -v ${PWD}:/home/datacontract datacontract/cli
Docker compose integration
We’ve included a docker-compose.yml configuration to simplify the build, test, and deployment of the image.
Building the Image with Docker Compose
To build the Docker image using Docker Compose, run the following command:
docker compose build
This command utilizes the docker-compose.yml to build the image, leveraging predefined settings such as the build context and Dockerfile location. This approach streamlines the image creation process, avoiding the need for manual build specifications each time.
Testing the Image
After building the image, you can test it directly with Docker Compose:
docker compose run --rm datacontract --version
This command runs the container momentarily to check the version of the datacontract CLI. The --rm flag ensures that the container is automatically removed after the command executes, keeping your environment clean.
Related Tools
- Entropy Data is a commercial tool to manage data contracts. It contains a web UI, access management, and data governance for a data product marketplace based on data contracts.
- Data Contract Editor is an editor for Data Contracts, including a live html preview.
License
Credits
Created by Stefan Negele, Jochen Christ, and Simon Harrer.
![]()
